Introdução
O Raspberry foi um sucesso desde o seu lançamento e continua a fascinar programadores, makers, hackers, estudantes e até cientistas, pela sua performance e baixo custo.
São sistemas SoC (System on a Chip), de baixo custo, baseados em arquitectura ARM, com muito potencial por explorar e pelo seu baixo consumo energético tornam-se equipamentos de eleição para pequenos e grandes projectos.
Processamento paralelo
Nos últimos anos a evolução dos processadores foi confrontada com as limitações ao aumento da frequência do ciclo do relógio. Com efeito, cada vez que se aumenta a frequência do relógio, aumenta o consumo de energia e o calor produzido de forma proporcional, o que sugere a aproximação de limites físicos dos circuitos.
Assim, como resultante do melhoramento do processo de fabrico dos circuitos integrados, em consonância com a Lei de Moore que estabelece que o número de transístores duplica cada dois anos, a resposta no mercado dos processadores passou por introduzir mais processadores no mesmo chip (multi-núcleo), aumentando a capacidade de processamento do chip, sem sofrer os problemas de eficiência energética e controlo de temperatura associados ao aumento da frequência do ciclo de relógio dos processadores “convencionais”. Esta alternativa engenhosa, de aumentar o desempenho do processamento, pela via do paralelismo por hardware tem vindo a impor-se tanto no mercado doméstico, como no das máquinas de elevada exigência.
O paralelismo oferece a grande vantagem de reduzir o tempo de processamento de grandes volumes de dados e cálculos matemáticos complexos, pela via do processamento paralelo com recurso a múltiplos nós, com um ou mais processadores por nó.
O tempo de processamento de um determinado input é normalmente proporcional à quantidade de dados de entrada, podendo tornar-se um factor limitativo quando existem cálculos computacionalmente intensivos ou com grandes volumes de dados. Assim, tendo em conta a consolidação das tecnologias associadas ao paralelismo ao longo dos últimos anos e a existência de sistemas de computação paralela acessíveis à comunidade, pode considerar-se inevitável o recurso ao paralelismo para minimizar o tempo consumido no processamento de dados.
O processamento paralelo é particularmente útil quando o volume de dados a serem processados não depende recursivamente dos outputs uns dos outros, podendo ser divido em blocos e estes, processados simultaneamente. Este tipo de problema, conhecido como embaraçosamente paralelo, consiste na divisão de trabalhos entre todas as “entidades” de processamento disponíveis, no processamento independente do trabalho enviado para cada “entidade” e por fim na junção dos resultados para obtenção do output final.
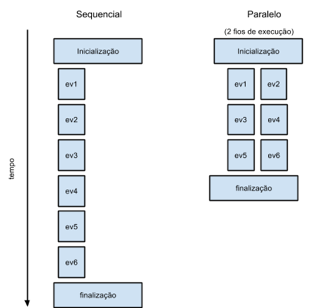
Quando um mesmo problema tem a oportunidade de ser executado com o dobro dos recursos computacionais é expectável que o tempo de execução total seja reduzido para a metade, no entanto, isto só é verdade em casos muito específicos explicados mais à frente.
Segundo a Lei de Amdahl, o tempo total de execução T, utilizando N entidades de processamento, pode ser reduzido para o limite teórico T(N) depende da fracção B do problema que não pode ser computada em paralelo, de acordo com a seguinte equação:
T(N) = T(1) (B + 1/N (1 – B))
Não obstante à melhoria máxima teórica prevista pela Lei de Amdahl, o ganho oferecido pelo paralelismo pode ser limitado por vários outros factores. Um dos principais factores limitativos do ganho de desempenho através do paralelismo é a largura de banda de acesso aos dados, uma vez que a capacidade de cálculo dos processadores atuais supera habitualmente a largura de banda de carregamento de informação, quer estejam na memória, em discos ou na rede.
O desfasamento da velocidade do processador em comparação com os dispositivos de armazenamento é tão grande que em muitos tipos de problema não é possível manter as unidades de processamento ocupadas durante todo o tempo, porque mesmo com grandes optimizações nos padrões de acesso à memória, com intuito de maximizar a utilização dos vários níveis de memória cache, e com esforços para maximizar a largura de banda dos sistemas de discos rígidos, os processados acabam por passar a maior parte do tempo ociosos a espera de receber dados para processar.
A situação é agravada quando os acesso os dados estão em sistemas de armazenamento permanente em discos magnéticos comuns, tais como o IDE, SCSI, SAS, SATA, mesmo quando ligados em RAID. A investigação em entrada/saída de dados tem vindo a proporcionar avanços significativos nos sistemas de armazenamento de informação.
Aos factores acima referidos deve-se acrescentar a sobrecarga em tempo de processamento resultante da execução de código associado à gestão do paralelismo que pode ser tanto mais relevante quanto menor for a granularidade do paralelismo. Por outras palavras, devem ser tidas em conta as possíveis perdas resultantes da implementação do paralelismo, ou seja, na generalidade dos casos é preferível aumentar o grão da secção paralela, por oposição ao paralelismo de grão-fino.
Outros factores relevantes surgem quando a zona paralela contém sincronizações, seja por limitações da implementação, ou por requisitos do problema que vêm a traduzir-se em “engarrafamentos” no desempenho, impedindo assim a obtenção de resultados mais próximos dos que seriam os teoricamente expectáveis, segundo a lei de Amdahl.
MPI (Message Passing Interface)
O MPI é um modelo de programação paralela para multiprocessamento baseado em message-passing, passagem-de-mensagem. Resumidamente consiste num conjunto de chamadas a bibliotecas que permitem aos multi-processos comunicarem entre si. Existem diversas implementações de MPI, no entanto na configuração que é apresentada abaixo apenas é referida a implementação MPICH.
As principais vantagens do MPI residem na escalabilidade, compatibilidade, mesmo em sistemas de memória partilhada, disponibilidade ampla e portabilidade. Como não existe “bela sem senão”, as desvantagens do MPI centram-se na curva de aprendizagem que tende a ser longa e no facto de não permitir paralelização incremental.
Só para contextualização histórica, o MPI começou a ser desenvolvido em finais da década de oitenta do século passado, e só tomou alguma “expressão maior” em Novembro de 1992, aquando da reunião do grupo de trabalho criado para dar continuidade ao processo de padronização de Message-Passing em ambientes de memória distribuída. Nessa reunião foi apresentado o primeiro esboço da interface de message-passing MPI1 e criado o MPI Fórum. Cerca de ano e meio mais tarde em 1994 foi disponibilizado para domínio público uma versão do padrão MPI.
Tem vindo a ser desenvolvido o padrão e desenvolvidas diversas implementações de MPI, para uma grande variedade de plataformas e arquitecturas de computador, no entanto essa discussão sai do âmbito deste artigo.
O Cluster com Raspberry Pi
O cluster com Raspberry Pi não é novidade, quanto mais não seja pelo baixo custo de cada computador Raspberry Pi e pela sua eficiência energética, o que o torna apelativo para soluções de processamento paralelo para fins académicos e “casuais”. Mas esta foi a primeira vez que me decidi a construir um, com apenas dois nós e que me surpreendeu pela positiva. Desta feita usei a distribuição GNU/Linux Raspbian e o software MPICH, uma implementação de MPI, distribuída sob o modelo open-source e com bom suporte para o Raspberry Pi.
Preparação
São precisos dois cartões de memória SD, no caso do Raspberry Pi Model B, como foi utilizado neste caso, os respectivos Raspberrys, um switch, cabos de rede para os ligar ao switch, um PC e alguma paciência, para seguir todos os passos da preparação. Então vamos começar:
- Fazer download da imagem da distribuição GNU/Linux Raspbian, do site http://www.raspberrypi.org/downloads/
No meu caso usei a imagem da versão 2012-10-28-wheezy-raspbian.zip, pois já a tinha nos cartões de memória com as devidas actualizações realizadas. Mas devem ser utilizadas versões mais recentes da imagem do Raspbian - Com o dd (GNU/Linux), o win32 disk imager (Windows) ou o Disk Utility (OS X), coloca-se a imagem do Raspbian descarregada anteriormente no cartão SD a ser utilizado no primeiro nó
- Uma vez colocado o cartão no Raspberry, basta ligá-lo à corrente, a uma “consola” ou à rede para lhe podermos aceder, e continuar para os passos seguintes de instalação e configuração
- Neste quarto passo, expande-se a partição do sistema operativo, de forma a ocupar todo o espaço disponível no cartão de memória, uma vez que se usou uma imagem e ela não utiliza a totalidade do espaço disponível. Para o fazer basta seguir os passos que se indicam:
$ sudo raspi-config- Escolher no menu a opção
expand_rootfs, que vai expandir a filesystem para todo o cartão de memória
- Pelas óbvias razões devemos mudar a password do utilizador root com que arrancamos o Raspberry pela primeira vez, utilizando o comando:
$ passwd - Faz-se reboot e inicia-se a instalação do MPICH
Instalação do MPICH
- Nesta fase começamos por actualizar o sistema operativo com os comandos:
$ sudo apt-get update
$ sudo apt-get upgrade - Agora, antes de descarregar o MPICH, devemos ter em mente o seguinte: se instalarmos o gfortran, vamos ter de o remover quando formos compilar o MPICH. Se não o instalarmos, não o teremos de remover. Caso se pretenda instalar, o comando é o seguinte:
$ sudo apt-get install gfortran - Como vamos descarregar o código fonte e compilar de seguida, neste passo cria-se a directoria para onde será extraído o ficheiro com o código fonte, utilizando os seguintes comandos:
$ mkdir /home/pi/mpich2
$ cd ~/mpich2 - Neste passo, vamos descarregar o código fonte do MPICH para o Raspberry, com o seguinte comando:
wget http://www.mcs.anl.gov/research/projects/mpich2/downloads/tarballs/1.4.1p1/mpich2-1.4.1p1.tar.gzConvém ter em atenção descarregar sempre a ultima versão, bastando para isso ver no site do MPICH. http://www.mpich.org/downloads/
- Agora descomprimimos o código fonte com o seguinte comando:
$ tar xfz mpich2-1.4.1p1.tar.gz - Antes de compilar, criamos directorias para armazenar os ficheiros do MPICH compilados, para ser mais fácil localizá-los de futuro e nos próximos passos, utilizando os seguintes comandos:
$ sudo mkdir /home/rpimpi/
$ sudo mkdir /home/rpimpi/mpich2-install
Aproveitamos a criação de directorias para criar uma para as builds, evitando com isto misturar ficheiros de builds com o código fonte:
$ mkdir /home/pi/mpich_build - Neste passo e dada a simplicidade, optei por incluir alguns procedimentos no mesmo passo. Vamos preparar a build que vamos usar. Como são procedimentos que no meu caso ainda demoraram um pouco, recomendo a quem esteja a seguir estes passo, seguir o meu exemplo e ir buscar uma caneca de café, ou chá, conforme o gosto! Vai dar jeito para o resto das tarefas!
$ cd /home/pi/mpich_build
$ sudo /home/pi/mpich2/mpich2-1.4.1p1/configure -prefix=/home/rpimpi/mpich2-install - Preparada a build que vamos usar no Raspberry, hora de make: e como isto demora, aproveita-se a bebida do passo 7, para “aquecer”! No meu caso foi a bebida e o “jornal das duas” na TV. É um procedimento demorado, mas está quase, é precisa paciência.
$ sudo make
$ sudo make install - Neste momento com o MPICH compilado chegamos quase ao momento de instalar, mas antes disso, acrescentamos à
$PATH, a path de instalação:
$ export PATH=$PATH:/home/rpimpi/mpich2-install/bin
Caso seja nossa ideia acrescentar esta path à $PATH de forma permanente, editamos o ficheiro .profile e acrescentamos as linhas como se segue:
$ export PATH=$PATH:/home/rpimpi/mpich2-install/bin
Caso o utilizador prefira, poderá seguir as seguintes instruções em alternativa à instrução anterior:
$nano ~/.profile
# Add MPI to path
PATH="$PATH:/home/rpimpi/mpich2-install/bin" - Verificamos se a instalação foi executada, com os seguintes comandos:
$ which mpicc
$ which mpiexec - Voltamos para a directoria home e criamos uma directoria de testes:
$ cd ~
$ mkdir mpi_testing
$ cd mpi_testing - E estamos quase no primeiro teste! Sim, demorou, foi cansativo, mas vale bem a pena. Mas antes do teste uma última configuração:
$ nano machinefile
Acrescentamos numa única linha o IP do Raspberry, no meu caso 192.168.5.2 - E o teste propriamente dito, com o seguinte comando:
$ mpiexec -f machinefile –n 1 hostnameO output do comando deve ser o nome do Raspberry, por default será
raspberrypi - E pronto, o “nó master”, está pronto a funcionar! Até aqui pode ter sido aborrecido e o exemplo já pronto para testar não é um “olá mundo” como seria expectável. No MPICH vem por default um exemplo em C para calcular o valor de pi. Podemos executá-lo da seguinte maneira:
$ cd /home/pi/mpi_testing
$ mpiexec -f machinefile -n 2 ~/mpich_build/examples/cpi
O output será algo como:
Process 0 of 2 is on raspberrypi
Process 1 of 2 is on raspberrypi
pi is approximately 3.1415926544231318, Error is 0.0000000008333387
Criando o segundo nó
Feito tudo até aqui, chegou a hora de criar uma imagem do cartão de memória usado no Raspberry, para criarmos os nós do MPICH. Esta fase difere conforme o sistema operativo que estamos a usar, seja Windows, GNU/Linux ou OS X.
- Primeiro passo é fazer o shutdown ao Raspberry, com o seguinte comando:
$ sudo poweroff - Agora retiramos o cartão de memória e utilizamos um software para criar a imagem do cartão de memória em ficheiro, para utilizar no segundo cartão de memória. Conforme o sistema operativo que se esteja a utilizar, o software vai variar. No meu caso foi o dd, pois fiz todos os passos em GNU/Linux. Temos de escolher um nome para a imagem, e como neste caso é do nó principal (master) ficaria algo como
raspbian_backup_mpi_master.img. - Feito o passo anterior, agora é fazer o inverso (gravar a imagem num novo cartão de memória), que será usado no 2º nó do Cluster e servirá para criarmos os restantes nós.
- Ligado o segundo Raspberry e contando que a rede esteja a fornecer o serviço de DHCP, basta executar o comando ifconfig para ver o endereço IP do segundo Raspberry.
Configurando o segundo Raspberry
Nesta fase vamos configurar o segundo nó do cluster, no segundo Raspberry que decidamos usar.
Todos os comandos que se seguem, deve ser executados no nó principal do nosso cluster MPI, neste caso o nosso primeiro Raspberry.
- Ligados por SSH ao nosso Raspberry principal (nó master), começamos por criar um key-pair (par de chaves) RSA para não termos de estar sempre a introduzir a password entre nós do cluster. Esta configuração pode ter outras aplicações, por exemplo se temos um Raspberry ligado a uma rede pública e queremos alguma segurança adicional. Para configurar correctamente executamos os seguintes comandos:
$ cd ~
$ ssh-keygen -t rsa –C “raspberrypi@raspberrypi”Escrevemos uma palavra passe à escolha, mas não convém, apesar de ser possível, deixar a palavra chave vazia.
De seguida executamos o seguinte comando para criar o ficheiro com as chaves que serão usadas e copiá-las para o segundo Raspberry:
$cat ~/.ssh/id_rsa.pub | ssh pi@192.168.5.3 "mkdir .ssh;cat >> .ssh/authorized_keys" - Agora ligamos ao segundo Raspberry utilizando ssh com o seguinte comando:
$ssh 192.168.5.3 - Uma vez ligados ao segundo Raspberry, se executarmos o seguinte comando:
$ ls –al ~/.ssh
Verificamos que o ficheiroauthorized_keysjá existe no segundo Raspberry. Isto é importante, porque de agora em diante não temos de digitar a password a cada autenticação entre nós do cluster. - Uma vez ligados ao segundo Raspberry vamos editar o ficheiro
machinefileonde estão os endereços das máquinas (nós) do nosso cluster, com o seguinte comando:
$ nano machinefileNeste ficheiro colocamos os IPs das duas máquinas que compõe o cluster. No meu caso:
192.168.5.2
192.168.5.3Gravamos o ficheiro e temos o Cluster com dois nós pronto a testar!
Antes de testar convém lembrar que não alteramos o nome do segundo Raspberry, por isso pode eventualmente gerar alguma confusão. No meu caso alterei manualmente, mas creio que em cenários com diversos hosts seria mais simples criar um script para alterar os hostnames.
Testando o Cluster com dois Raspberry
- No nó principal digitamos o comando abaixo, para executar o mesmo exemplo que executámos inicialmente. A diferença agora é que serão dois nós a executar o programa exemplo. Relembremo-nos que não alteramos o nome de host de nenhum dos Raspberry:
$ cd /home/pi/mpi_testing
$ mpiexec -f machinefile -n 2 ~/mpich_build/examples/cpiAo executar o código reparamos que o output é ligeiramente diferente:
Process 0 of 2 is on raspberrypi
Process 1 of 2 is on raspberrypi
pi is approximately 3.1415926544231318, Error is 0.0000000008333387
Note-se que apenas tivemos de reintroduzir a palavra-chave que criamos na configuração das chaves RSA uma vez, se repetirmos, não será pedida a chave.
Criando mais nós
Para criar mais nós na rede os passos são semelhantes, mas um pouco mais simplificados, como veremos de seguida:
- Primeiro passo é fazer o shutdown ao Raspberry, com o seguinte comando:
$ sudo poweroff - Agora retiramos o cartão de memória e utilizamos um software para criar a imagem do cartão de memória em ficheiro, para utilizar no segundo cartão de memória. Conforme o sistema operativo que se esteja a utilizar, o software vai variar. No meu caso foi o dd, pois fiz todos os passos em GNU/Linux. Temos de escolher um nome para a imagem, e como neste caso é do nó “trabalhador” (worker) ficaria algo como
raspbian_backup_mpi_worker.img. - Feito o passo anterior agora é fazer o inverso (gravar a imagem num novo cartão de memória), que será usado no novo nó do cluster e servirá para criarmos os restantes nós.
- Inserimos o cartão agora gravado no terceiro Raspberry e ficamos com três Raspberrys funcionais, e assim por diante.
Conclusão
Como se pode ver ao longo do artigo, existem diversas razões para se recorrer à computação paralela e o acesso e montagem de clusters de computadores tornou-se bastante mais simplificado. Neste artigo apenas se pretende apresentar de forma simples as instruções necessárias para construir um cluster MPI de baixo custo, recorrendo aos pequenos computadores Raspberry Pi, pelo que não se explica em detalhe programação paralela, nem computação paralela. Existe diversa documentação de qualidade disponível, para além do artigo Paralelização de aplicações com OpenMP publicado na edição nº 46 da Revista PROGRAMAR. Boas experiências.